探索我们精心策划的AI文章集合,涵盖人工智能、机器学习、AI工具等多个领域
RealRestorr,迈向具有大规模图像编辑模型的通用现实图像修复,用于利用大规模图像编辑模型实现可通用的真实世界图像恢复。
MACRO,推进结构化长上下文数据的多参考图像生成,涵盖四个任务类别—— 定制 、 插图 、 空间和时间—— 分布在四个图像计数括号内(1–3、4–5、6–7、≥8 张参考图片)。
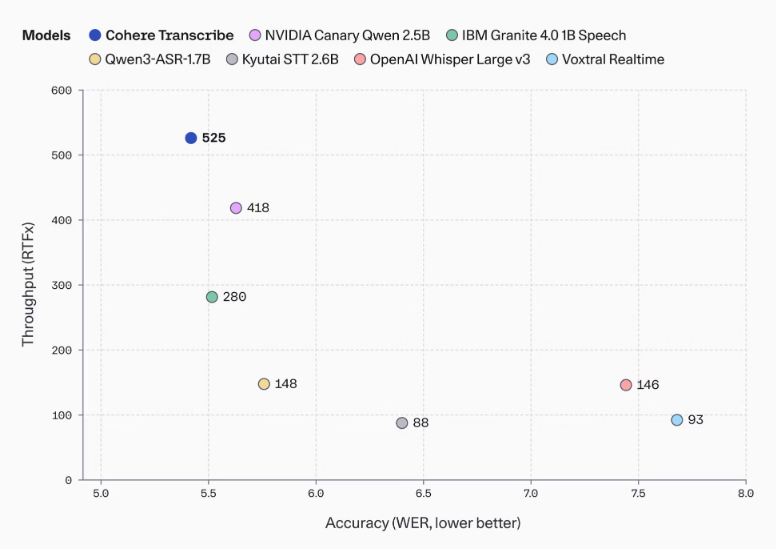
Cohere Transcribe,开源的语音识别模型,采用 2B 参数专用音频输入、文本输出,支持 14 种语言。
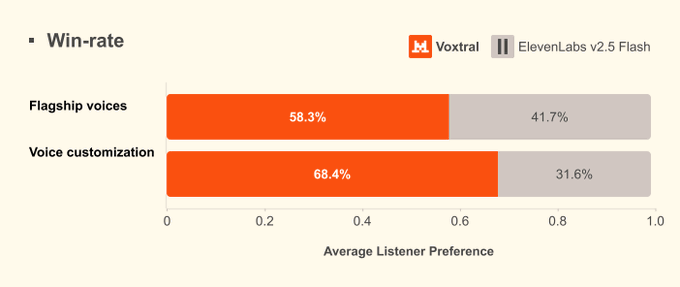
Voxtral TTS,Mistral开源的文本转语音模型,速度快、即时适应,并为语音代理提供逼真的语音。
MinerU-Diffusion,基于扩散的文档 OCR 框架,通过引入分块扩散和不确定性驱动的课程学习,它实现了最高3.2×的解码速度,同时提升了鲁棒性,减少对语言先验的依赖。
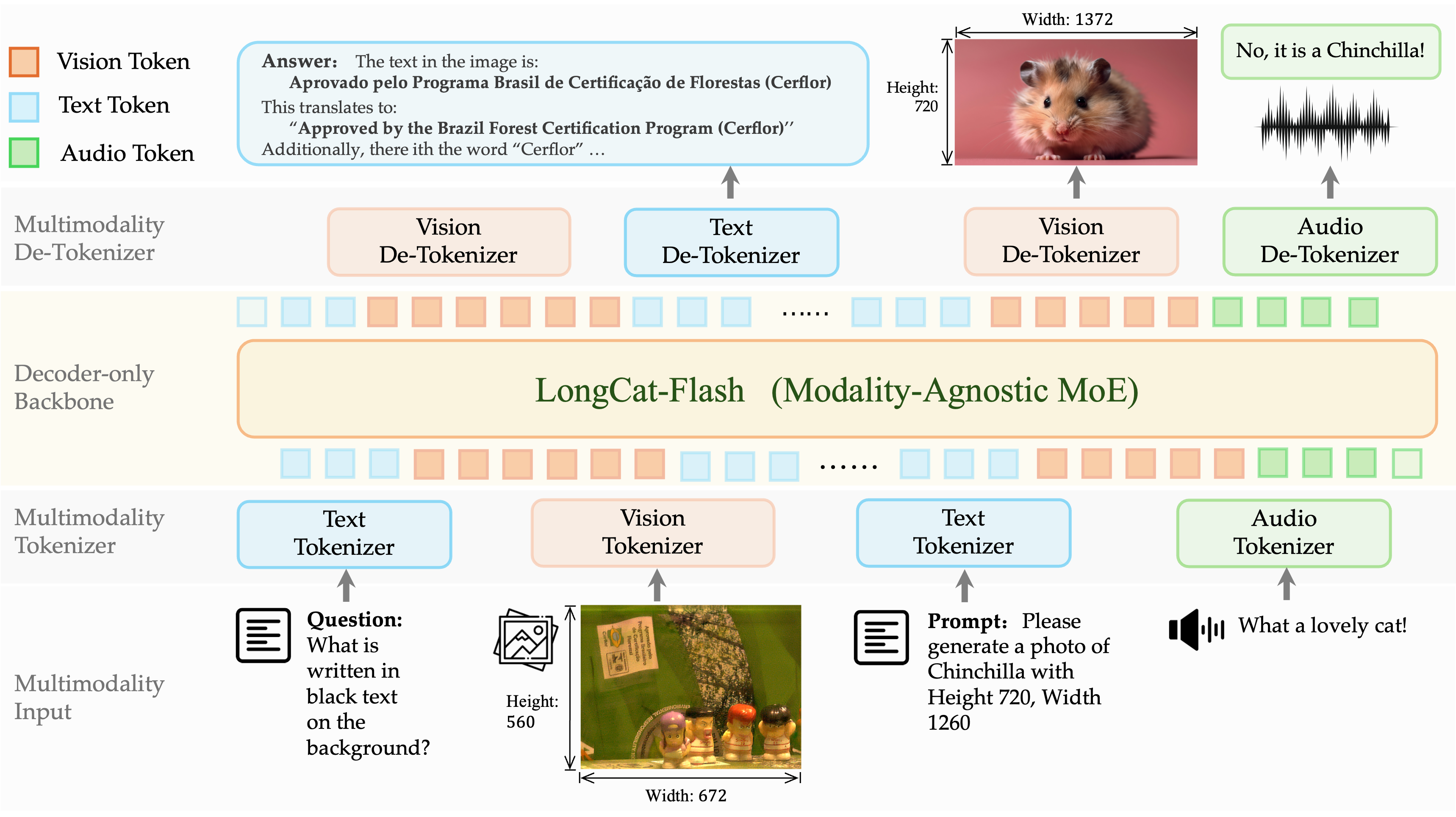
LongCat-Next,开源的原生多模态模型,将语言、视觉和音频整合为统一的离散自回归模型,在单一自回归目标下处理文本、视觉和音频。
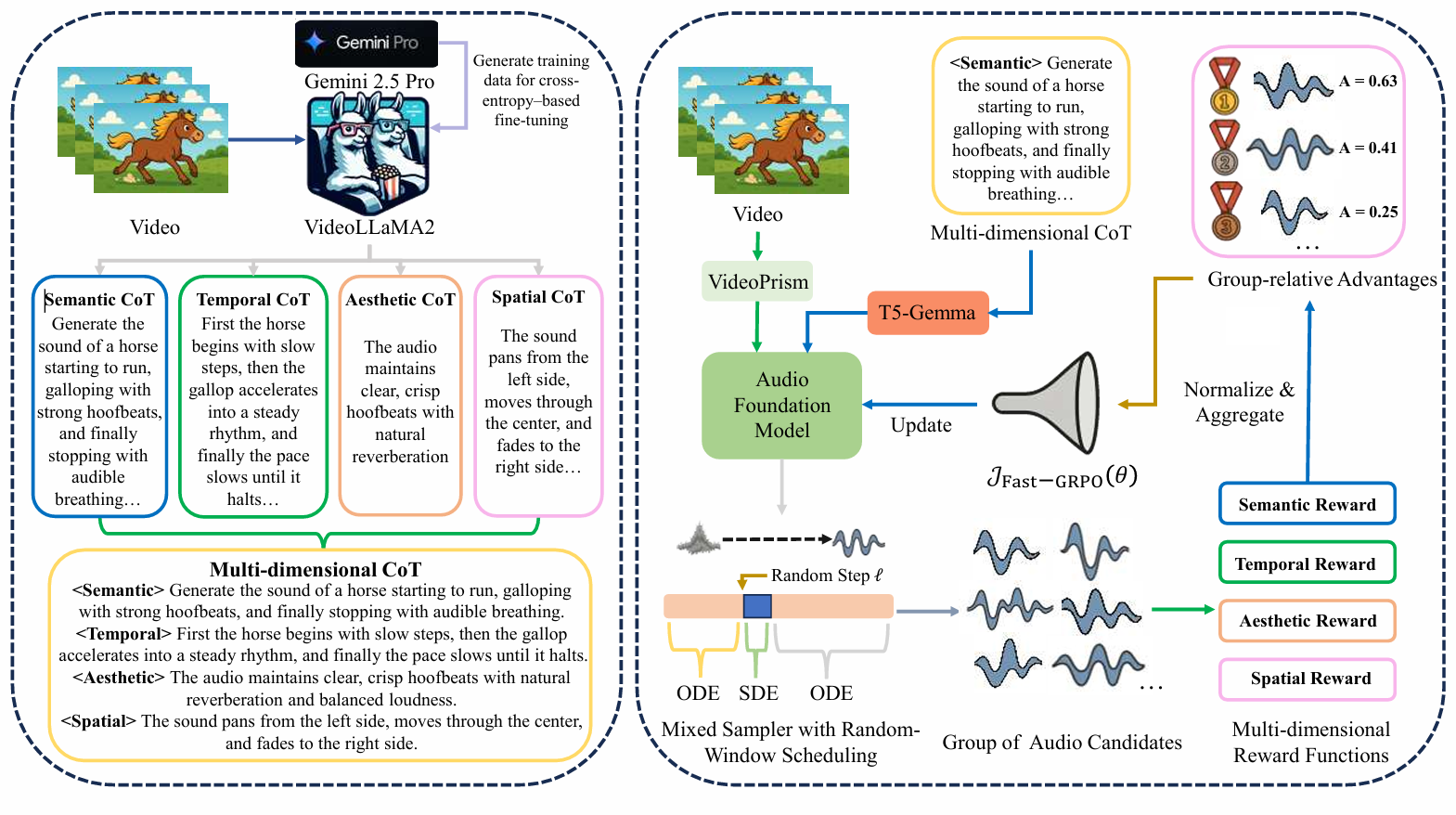
PrismAudio,阿里开源的视频生成音效模型,在 ThinkSound 的基于 CoT 的 V2A 框架基础上,PrismAudio 进一步将单步推理分解为四个专用 CoT 模块——语义 、 时间 、 美学和空间 ——每个模块都具有针对性的奖励函数,实现多维强化学习优化,同时提升所有感知维度的推理能力。
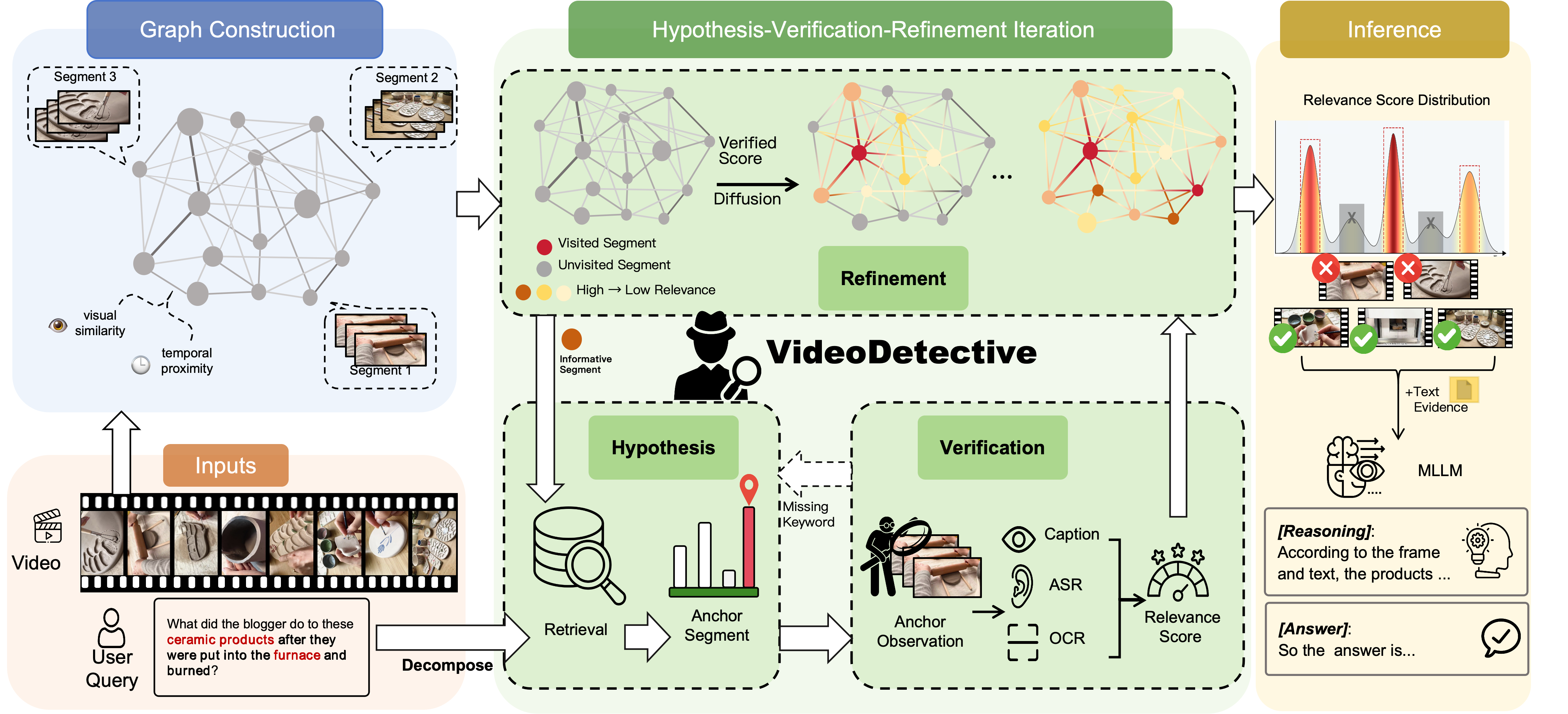
VideoDetective,长视频理解的即插即用推理框架,通过外部查询和内部相关性进行长视频理解的线索搜寻。